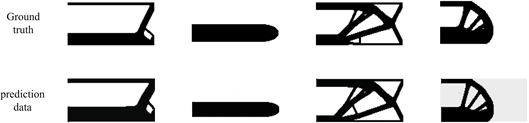1. 引言
传统的拓扑优化方法主要包括固体各向同性材料惩罚法SIMP (Solid Isotropic Material with Penalization) [1] [2] [3] 、水平集法(Level set) [4] [5] [6] 、均匀化法(Homogenization Method) [7] [8] [9] 以及渐进结构优化法ESO (Evolutionary Structural Optimization method) [10] [11] [12] 等。这些方法在求解过程中均依赖于有限元法,通过对设计区域进行离散化处理,将其划分为一系列小的单元或元素。随后,对这些单元进行迭代计算,以寻求满足所有约束条件和性能要求的最优解。尽管这些方法在各自的领域中都取得了显著的成果,但它们的共同特点是计算量大。由于需要反复迭代和计算,传统的拓扑优化设计往往非常耗时。特别是对于精细化结构部件的拓扑优化,随着结构单元数量的增加,导致时间成本和算力成本会显著增加,这使得传统方法很难胜任紧急精细工程。
随着机器学习和深度学习的快速发展以及图像生成技术的逐渐成熟,这使得深度学习和拓扑优化的跨学科结合也迫在眉睫。拓扑优化是一种寻找最优结构的设计方法,而深度学习则是一种强大的学习模型,可以从大量数据中学习复杂的映射关系。如果在拓扑优化中引入深度学习,可以利用其高维映射关系而无需迭代即可得到最优解的优势,大大降低时间成本和算力成本。具体来说,可以通过训练深度神经网络来学习已有的优化结果中的约束条件、物理信息和最优结构之间的隐式映射关系,然后通过这个映射关系实现预测。
优化结构的探索可分为三个步骤:直接从噪声中预测优化结构,使用少量迭代计算预测最终优化结构,在边界条件的监督下预测优化结构。生成对抗网络(Generative Adversarial Network, GAN) [13] [14] [15] 在直接从噪声中预测有着较好的表现,Rawat [16] 引入的CWGAN网络也提出了不错的新思路。但是这些都是无监督生成,是一种图像的随机生成,因此无法满足工业需求。第二种探索是使用少量迭代计算预测最终优化结构,其中较为经典的就是Sosnovik [17] 等人提出的CNN,在半成品结构进行无迭代的更精细化预测。第三种就是从边界条件情况下预测,条件生成对抗网络(Conditional Generative Adversarial Network, CGAN) [15] [18] [19] 是一种生成对抗网络,可用于控制生成器在给定条件信息的情况下生成特定类型的真实数据样本。Yonggyun Yu [20] 等人利用这个网络进一步提高了拓扑优化的预测能力,然而最终实测下来效果并没有那么优秀。
本文将提出TOuCD模型(Topology Optimization using Conditional Diffusion Modes),该模型是一种有监督模型,能够预测生成特定的结果,TOuCD的预测能力和效果将优于上述探索的结果,同时也比传统的拓扑优化方法更加节省算力成本
2. 相关技术基础
2.1. 拓扑优化
拓扑优化是一种用于寻找最优结构设计的数学方法。拓扑优化通常将结构的密度场 表示为介于0~1的值,即可将拓扑优化问题转化为连续优化问题。拓扑优化通过最小化结构材料的体积或重量,获得最佳材料分布。不仅可以帮助工程师设计出满足各种约束条件的优化结构,还能够降低实验成本。拓扑优化的目标函数大致可以表示为:
(1)
x表示物理域的材料分布, 所有约束的条件集合。
SIMP是Bendsoe [21] 等人提出的一种拓扑优化方法。SIMP首先将整个物理域划分为n × m个单元格,每个单元格用0~1的数值表示密度场大小,SIMP通过使用惩罚系数p迫使密度场尽可能趋近于0或者1,其中0表示空气或者没有材料,1表示完全填充材料。SIMP的目标函数是用于分析结构的形变程度,因此目标函数越小结构越稳定,其数学模型如公式(2)所示。
(2)
式中,x为设计变量(物理域), 是全局位移, 为全局刚度矩阵, 单元物理域, 是SIMP的惩罚系数, 单元位移, 单元刚度矩阵, 和 分别为材料体积和设计域体积,两个的比值为体积分数 ,F为受力载荷, 为最小体积。
2.2. 扩散模型
DDPM (Denoising Diffusion Probabilistic Models)是Jonathan Ho [22] 等人提出的一种合成高质量图像模型,被称为扩散模型(Diffusion Model)。扩散模型是一种无监督生成模型,生成效果极佳,在CIFAR10数据集上获得了出色的表现,IS (Inception Score)评价指标得分9.46,FID (Fréchet Inception Distance)评价指标得分3.17。在256x256 LSUN上,扩散模型的效果达到了和Progressive GAN相似的效果。
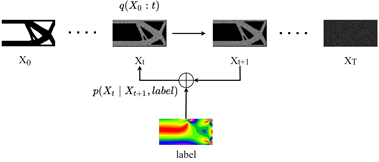
如图1所示,DDPM在训练的过程中可分为两大环节:数据集加噪过程、模型训练(去噪过程)。从 到 的过程就是数据集加噪过程,向定初始图像 中逐步添加高斯噪声,加噪过程持续 次,产生 个加噪图像。这一目的是破坏图像,理论上 越接近无穷大,图像 越趋近于高斯噪声。
到 的过程是去噪过程,该过程无法使用数学方法直接计算,因此需要训练出一个合适的网络模型对其逐步去噪,逐步从 , ,…,复原出没有噪声的原图像 。所以加噪过程可以看作在为去噪过程构建训练模型的数据集。
DDIM [23] 对DDPM模型的加噪环节做了优化。因为DDPM在加噪过程中采用了一阶马尔可夫假设,导致需要很大的步长才能达到好的效果。而DDIM采用线性采样分布的方法为原图像加入噪声,即在第T步,无论 设置的值为多少,在这一步加噪后的图像都接近高斯噪音,提升了加噪效率。在本文提出的TOuCD就是在DDIM模型的基础上修改来的。
3. TOuCD
TOuCD模型是扩散模型在拓扑优化领域中的首次探索。扩散模型是一种无监督图像生成模型,整个训练过程包括加噪和降噪两大部分。加噪过程是一种数学方法,通过添加入高斯噪声逐渐把原始图像变成质量较差的图像;去噪过程无法采用数学方法直接求出原始图像,因此通过训练合适的网络模型完成这个去噪任务。在扩散模型完成训练之后,即可从随机噪声生成类似与数据集的高质量图像,虽然生成图像质量优秀,但是由于其无监督信息的特点无法生成特定结果,因此无法适应拓扑优化的求解过程。为此本文尝试在扩散模型上加入监督信息以适应拓扑优化的需求,提出TOuCD。
3.1. 网络模型
如图2所示提出的TOuCD网络流程结构,此模型是建立在扩散模型的基础之上。由于DDIM加噪思想的先进性,无需逐步对原始图片进行加噪,可直接求出对原始图像 加噪t步的结果 。TOuCD和DDIM的最大不同点是DDIM的训练和预测都是一种无监督过程,仅是前者时刻和后者时刻的高维映射,而TOuCD在训练的过程中,加入了标签信息,图中 是模型预测结果。加入的标签信息可以是拓扑优化中的体积分数、应力、应变等其他边界条件,为此本文测试了多种不同输入组合对最终结果的影响。正是这些监督信息的加入,在测试环节可以约束随机噪声生成拓扑优化想要的结果,让拓扑优化结果更有物理意义。
在数据集中每组标签信息对应一个拓扑优化结果,即原始图像 。加噪是对拓扑优化结构的处理,去噪过程就是对拓扑优化结果的逐步预测,在这个过程中每一步都有监督信息,测试环节也是如此。
3.2. 网络结构
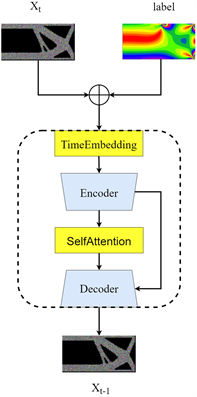
网络模型如图3所示。TOuCD由时间编码(Time Embedding)、编码器(Encoder)、自注意力机制(Self Attention)和解码器四部分组成。网络的工作步骤如下:1) 时间编码,将标签信息、加噪图像 和时间t编码为128 * 4的特征图,然后通过两个线性层和一个激活层。这一步是为了给监督信息和噪声图像加上时间戳,便于网络识别当前网络步数。2) 特征提取,编码器中逐层提取输入数据的特征信息,首先通过一个卷积层,再通过若干个残差模块和卷积层组合成的网络,这一步是将输入图像映射到低维度的特征空间进行数据分类以分析,目的是获取高纬度的语义信息。3) 自注意力机制,这一部分包含两个残差模块和一个自注意力模块,目的是更加有效的提取特征图像,从而提高网络生成效果。4) 图像还原,这一部分由若干个残差模块和卷积层组成,其中层数和特征提取层数相同,并且拥有和Unet模型类似的以跳接方式进行特征融合的步骤。这些网络层主要任务是:逐步恢复输入图像的低级特征并收集编码器提取的语义信息,将相关信息对应到生成图像的像素点上,最终输出生成的图像。
3.3. 损失函数
在实验中,模型选择Smooth L1损失函数,其公式如3所示。均方误差和绝对值误差是最常用于图像生成的损失函数,他们各自拥有自己的优缺点。绝对值误差损失函数的梯度值稳定,使得训练平稳;不易受离群点(脏数据)影响,所有数据一视同仁。但E=0 (E表示预测值与生成值之间的差值)处不可导,可能影响收敛;E值小时梯度大,很难收敛到极小值,只能通过降低学习率提高其收敛效果。绝对值误差损失函数平滑可导、E较大时梯度大,收敛快;E较小时梯度小,容易收敛至极值点。但是训练初期E较大导致梯度大,更新幅度太大使得训练不稳定,容易出现梯度爆炸现象;受离群点影响大,容易在离群点的干扰下大幅更新,使拟合函数偏向离群点而导致准确率低。Smooth L1是这两个损失函数的结合体,在根据生成数据与参考数据之间差距选用不太计算方法。
(3)
式中, 为在监督信息干预的情况下第t步骤的预测数据, 通过SIMP计算出来的拓扑优化结果并添加t步高斯噪声。
4. 实验
4.1. 实验环境与参数
实验的具体设置和TOuCD模型的参数如下:batch设置为8,epoch的数量设置为240000,加噪步数根据实验设定,采用线性加噪方法,加噪程度区间[0.0001, 0.01],学习率为0.00002,网络采用Adam优化算法。相关实验在Ubuntu 20.04.5 LTS系统下运行,CPU :11th Gen Intel (R)Core(TM)19-11900K 3.50 GHz,内存:32 G,GPU:NVIDIA GeForce RTX 3090。
4.2. 数据集
实验中本文将整个数据集的80%用于训练,20%用于测试。生成数据集主要采用SIMP和FEM的传统计算方法生成,并保存为图像。具体参数设置如下:
设计域:64 * 128网格单元。
体积分数:0.3~0.5之间的随机值。
荷载:荷载分别为x轴方向的力和y轴方向的力,大小均为1,在设计域上随机给出方向和位置。
应力、应变:基于上述条件,采用FEM有限元法生成。
拓扑结构:根据上述条件使用SIMP生成。
4.3. 实验过程及分析
实验一
在实验中,设置加噪步数为500,监督信息为应变。训练测试结果如图4所示。图中结构效果较差,只有黑白分明的区域,这说明网络模型只明白了拓扑优化的任务需要保留可用的物理域,即黑色图像区域。出现这种情况的原因可能是加噪步数过少导致图与图间隔过大,模型不容易学到太多有效相关信息。为此计划通过修改部分参数重新训练测试。由于模型结果不佳,就不再展示损失函数效果图以及和其他模型结果对比表。
实验二
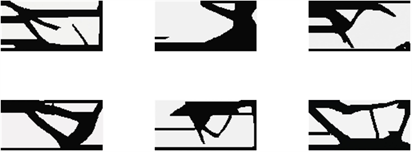
在此次实验中,设置加噪步数为700,监督信息依然为应变。训练测试结果如图5所示。此次效果相对于实验一效果有明显提升,在图中可以看出,已经有部分结构的轮廓特征,其中少部分结果已经很接近拓扑优化结果,如图5中第四个展示图。这说明,网络模型生成能力进一步提高,已经开始学习应变到拓扑优化结构的高维映射,只是这种学习能力还比较弱。同时也说明此次实验调试方向是正确的,为此决定继续加大加噪步数。显然现在结果依旧不好,因此也不展示损失函数以及与其他模型的对比效果图。
实验三
在此次实验中,设置加噪步数为1000,监督信息依然为应变。部分测试结果如图6所示,第一行图像展示的是SIMP方法计算出的结果,第二行图像展示的是模型预测出的结果。直观的去看,大部分生成结果符合拓扑优化的结构轮廓,而且基本没有噪音,这说明TOuCD模型可以完成传统的拓扑优化。同时也可以发现,在预测结构中发现出现了部分不属于结构中的部分,比如图6中部分预测结果出现了类似于边框的细线,同时预测结构的体积略大与参考结构的体积,因此暂时推测,由于没有考虑预测结构的体积分数导致这种情况的产生,为此打算在下次实验中,通过加入体积分数观察这种情况是否解决。
损失函数如图7所示,图中展示了前6200 epoch损失函数结果。通过观察曲线,可以明显看出模型快速收敛,在2000个步骤之后,损失函数开始趋于稳定,并在允许的误差范围内波动,这表明模型已经取得了相对稳定的性能。表1中展示了TOuCD和其他模型预测结果的对比,可以看出TOuCD模型暂时落后其他两个模型,因此TOuCD还需要进一步优化。
实验四
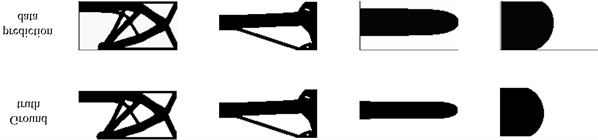
为了验证实验三中的猜想,本次实验修改了网络模型输入和部分参数。监督信息改为应变和体积分数,其他条件保持一致。由于在实验三中,模型预测效果已经比较好,所以两个实验最大的差距在细节部分,这此次实验中,改善了体积略大的问题,以及在边缘处出现不应该存在的物理结构。图8展示了本次实验的部分结构示意图。图中第一个行图像表示金标准数据可视化结果,第二行图像是预测模型预测结构的可视化效果图。在视觉上,预测数据和真实数据已基本吻合,也没有不该存在的物理域存在情况,说明这次模型调试比较成功,之前问题也基本解决。
在实验三中,观察到模型的预测能力相对逊色,与其他两个模型相比表现不佳。因此,在这次的预测中,再次与这两个模型进行对比,并将对比结果总结在表2中,以便更清晰地展示模型之间的性能差异。数据显示TOuCD预测能力已经超越cGAN的预测能力,虽然此次模型预测效果依旧逊色与TopologyGAN,但是TOuCD预测的拓扑优化结构轮廓更加完美,也没有像TopologyGAN出现不属于拓扑结构的噪声,也没有出现类似于TopologyGAN的噪音。实验后,把TopologyGAN预测结果、TOuCD预测结果与真实拓扑结构做了对比,最终发现TopologyGAN预测结果在体积分数上的表现能力依旧比TOuCD生成能力更强,这可能导致TopologyGAN在数据上看起来更好的原因。
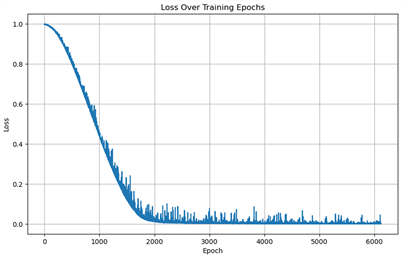
图9是本实验的损失函数展示图,图中展示了前6200 epoch损失函数结果。通过观察曲线,可以明显看出模型快速收敛,在2000个步骤之后,损失函数开始趋于稳定,并在允许的误差范围内波动,这表明模型已经取得了相对稳定的性能。其整体效果和实验三比较相似,都是快速收敛并趋向于稳定,只有损失函数的波动频率和幅度略有不同,出现这种情况的原因可能是加入体积分数后引起的,整体趋势相同可能是拓扑结构受应变的影响比较大。
5. 总结与展望
本文详细阐述了扩散模型的应用领域以及其特点。接着,介绍了为了满足拓扑优化需求而对模型架构进行的相应调整,以及模型重要参数和损失函数。最后,相继进行四个实验逐步升级改进,成功使TOuCD模型预测出拓扑优化结构。但是该模型在数据预测中需要预测1000步,虽然已经很大的节省了时间算力,但这不代表没有上升空间,在未来的工作中我们将会从损失函数和网络模型两个方面继续探索这种跨学科结合,进一步提升预测能力。
基金项目
本研究在烟台市科技创新计划项目2022XDRH016支持下完成。
参考文献
NOTES
*通讯作者。
Copyright © 2012-2021 首页-恒彩平台-注册登录站 备案号:琼ICP备xxxxxxxx号